Dies ist die Support Website des Buches:
Das Python Praxisbuch
Der große Profi-Leitfaden für Programmierer
Farid Hajji
Addison Wesley / Pearson Education
ISBN 978-3-8273-2543-3 (Sep 2008), 1298 Seiten.
13. Persistenz und Datenbanken¶
Serialisieren und Deserialisieren¶
Ein naiver Versuch mit str und eval¶
Die richtige Lösung mit pickle¶
Screenshots:
{kind=link}
class MyType(object):
def hello(self):
return 'hello!'
Picklen mit dumps und loads:
from cPickle import dumps, loads
obj = MyType()
obj_as_str = dumps(obj)
obj2 = loads(obj_as_str)
Picklen mit dump und load:
from cPickle import dump, load
out = open('/tmp/myobj.pickle', 'wb')
dump(obj, out)
out.close()
inp = open('/tmp/myobj.pickle', 'rb')
obj3 = load(inp)
inp.close()
Das funktioniert nur auf den ersten Blick scheinbar reibungslos:
from cPickle import dump, load
class MyType(object):
def hello(self):
return "hello!"
obj = MyType()
dump(obj, open('/tmp/myobj.pickle', 'wb'))
obj2 = load(open('/tmp/myobj.pickle', 'rb'))
Aber wenn der Typ MyType aus der Datei mytype.p kommt:
from mytype import MyType
from cPickle import dump
obj = MyType()
dump(obj, open('/tmp/myobj.pickle', 'wb'))
dann geht es:
>>> from cPickle import load
>>> obj2 = load(open('/tmp/myobj.pickle', 'rb'))
>>> obj2.hello()
'hello!'
URLs:
Persistente Dictionarys mit anydbm¶
Screenshots:
{kind=link}
Eine naive suboptimale Lösung¶
Die richtige Lösung mit anydbm¶
Ein persistentes Dictionary mit anydbm:
import anydbm
d = anydbm.open('/tmp/dictstore.db', 'c', 0600)
d['one'] = 'eins'
d['two'] = 'zwei'
d['three'] = 'drei'
d.close()
Besonderheiten von anydbm Dictionarys¶
Die anydbm-Architektur¶
Mehr Flexibilität mit bsddb¶
Ein sortiertes persistendes Dictionary mit bsddb:
import bsddb
d = bsddb.btopen('/tmp/dictstore2.db', 'c', 0600)
d['one'] = 'eins'
d['two'] = 'zwei'
d['three'] = 'drei'
d['four'] = 'vier'
d['five'] = 'fuenf'
d.sync()
d.close()
Screenshots:
{kind=link}
{kind=link}
Persistente Datenstrukturen mit shelve¶
class Personal(object):
'''A personal record for HR databases'''
def __init__(self, pid, firstname, middlename, surname):
self.pid = pid
self.firstname = firstname
self.middlename = middlename
self.surname = surname
def __str__(self):
return 'Personal(%s, %s %s. %s)' % (self.pid, self.firstname,
self.middlename, self.surname)
Eine umständliche Lösung¶
Man könnte shelve manuell mit anydbm und cPickle nachbilden:
from personal import Personal
from cPickle import dumps
import anydbm
d = anydbm.open('/tmp/personal.store', 'c', 0600)
p1 = Personal('0001', 'John', 'R', 'Doe')
d[p1.pid] = dumps(p1)
d.close()
und wieder auslesen:
>>> from cPickle import loads
>>> import anydbm
>>> d = anydbm.open('/tmp/personal.store', 'r')
>>> p1 = loads(d['0001'])
>>> p1
<personal.Personal object at 0x2843508c>
>>> str(p1)
'Personal(0001, John R. Doe)'
>>> p1.surname
'Doe'
Beim Verändern von Einträgen muss man aufpassen:
from cPickle import dumps, loads
import anydbm
d = anydbm.open('/tmp/personal.store', 'w')
p1 = loads(d['0001'])
p1.middlename = 'S'
d[p1.pid] = dumps(p1)
d.close()
Die shelve-Lösung¶
shelve benutzen:
from personal import Personal
import shelve
p1 = Personal('0001', 'John', 'R', 'Doe')
p2 = Personal('0002', 'Martin', 'S', 'Bishop')
p3 = Personal('U100', 'John', 'P', 'McKittrick')
s = shelve.open('/tmp/personal.shelve')
s[p1.pid] = p1
s[p2.pid] = p2
s[p3.pid] = p3
s.close()
Screenshots:
{kind=link}
shelve-Gotchas¶
shelve mit Gedächtnis¶
Die ZODB-objektorientierte Datenbank¶
ZODB installieren¶
Die ZODB benutzen¶
class Personal(object):
'''A personal record for HR databases'''
def __init__(self, pid, firstname, middlename, surname):
self.pid = pid
self.firstname = firstname
self.middlename = middlename
self.surname = surname
def __str__(self):
return 'Personal(%s, %s %s. %s)' % (self.pid, self.firstname,
self.middlename, self.surname)
from personal import Personal
import persistent
class PPersonal(Personal, persistent.Persistent):
'''A persistent Personal object'''
def __str__(self):
return 'PPersonal(%s, %s %s. %s)' % (self.pid, self.firstname,
self.middlename, self.surname)
Persistenz durch Erreichbarkeit¶
Worauf man bei ZODB achten muss¶
{kind=link}
Weiterführende Informationen¶
URLs:
- Die ZODB-Dokumentation
- ZODB/ZEO Programming Guide von A. M. Kuchling
- Introduction to the Zope Object Database von Jim Fulton
Ein Blogs-Backend mit ZODB¶
Comment, Article und Blog¶
#!/usr/bin/env python
# zcomment.py -- A ZODB-persistent Comment class.
from persistent import Persistent
class Comment(Persistent):
'''A Comment contains a simple text'''
def __init__(self, subject='Comment Subject', text='Comment Text',
author='Anonymous'):
self.subject = subject
self.author = author
self.text = text
def __str__(self):
return "Comment(subject='%s', author='%s', text='%s')" \
% (self.subject, self.author, self.text)
def __repr__(self):
return "<Comment subject='%s'>" % self.subject
#!/usr/bin/env python
# zarticle.py -- A ZODB-persistent Article class.
from persistent import Persistent
from BTrees.OOBTree import OOBTree
import time
class Article(Persistent):
'''An Article contains many comments'''
def __init__(self, title='Article Title', author='Article Author',
text='Article Text'):
self.title = title
self.author = author
self.text = text
self.comments = OOBTree()
self.lastcomment = 0L
def add_comment(self, comment):
self.lastcomment = self.lastcomment + 1L
self.comments['%08d' % self.lastcomment] = (comment, time.time())
def __str__(self):
result = []
result.append("Article(title='%s', author='%s',\n" \
% (self.title, self.author))
result.append(" text='%s',\n" % self.text)
for comment_id in self.comments:
thecomment, when_added = self.comments[comment_id]
result.append(" %s,\n comment_added=%s\n" \
% (str(thecomment), time.ctime(when_added)))
result.append(")")
return ''.join(result)
def __repr__(self):
return "<Article title='%s'>" % self.title
#!/usr/bin/env python
# zblog.py -- A ZODB-persistent Blog class.
from persistent import Persistent
from BTrees.OOBTree import OOBTree
import time
class Blog(Persistent):
'''A Blog contains many articles'''
def __init__(self, name='Blog Name', author='Blog Author',
descr='Blog description'):
self.name = name
self.author = author
self.descr = descr
self.articles = OOBTree()
self.lastarticle = 0L
def add_article(self, article):
self.lastarticle = self.lastarticle + 1
self.articles['%08d' % self.lastarticle] = (article, time.time())
def __str__(self):
result = []
result.append("Blog(name='%s', author='%s'\n" \
% (self.name, self.author))
result.append(" descr='%s'\n" % self.descr)
for article_id in self.articles:
thearticle, when_added = self.articles[article_id]
result.append(" %s\n article_added=%s\n" \
% (str(thearticle), time.ctime(when_added)))
result.append(")")
return ''.join(result)
def __repr__(self):
return "<Blog name='%s'>" % self.name
Das Blog-Backend BlogDB¶
#!/usr/bin/env python
# zblogdb.py -- A ZODB-persistent Blog system.
from ZODB import FileStorage, DB
from BTrees.OOBTree import OOBTree
import transaction
import logging
from zblog import Blog
from zarticle import Article
from zcomment import Comment
class BlogDB(object):
'''A persistent Blog ZODB'''
def __init__(self, zodbname='blogs', path_to_fs='/tmp/blogdb.fs'):
self.zodbname = zodbname
self.path_to_fs = path_to_fs
self.connect()
def connect(self):
self.logger = logging.getLogger('ZODB.FileStorage')
logger = self.logger
self.storage = FileStorage.FileStorage(self.path_to_fs)
self.db = DB(self.storage)
self.conn = self.db.open()
self.dbroot = self.conn.root()
if self.zodbname not in self.dbroot:
self.dbroot[self.zodbname] = OOBTree()
self.blogsdb = self.dbroot[self.zodbname]
def close(self):
self.conn.close(); self.conn = None
self.db.close(); self.db = None
self.storage.close(); self.storage = None
self.dbroot = None; self.blogsdb = None
def add_blog(self, newblog, commit=True):
"Add a new Blog object to the ZODB"
self.blogsdb[newblog.name] = newblog
if commit:
self.commit_changes()
def get_blog_names(self):
"Return a list of blog names"
return list(self.blogsdb.keys())
def get_blog_by_name(self, blogname):
"Given a blog name, return Blog object or None."
try:
return self.blogsdb[blogname]
except KeyError:
return None
def commit_changes(self):
transaction.commit()
def rollback_changes(self):
transaction.abort()
if __name__ == '__main__':
theblogdb = BlogDB()
DB-API 2.0 SQL-Anbindungen¶
SQLite-Anbindung mit sqlite3¶
Screenshots:
{kind=link}
{kind=link}
URLs:
- Homepage der SQLite3 C-Library
- Homepage des sqlite3 Python Moduls (ist aber in Python 2.5 und später integriert)
sqlite3 benutzen¶
Das sqlite3-Tool¶
URLs:
Manuell eine Tabelle anlegen:
$ sqlite3 /tmp/blogdb.sqlite3
SQLite version 3.4.1
Enter ".help" for instructions
sqlite> CREATE TABLE comments (
...> id INTEGER PRIMARY KEY AUTOINCREMENT,
...> subject TEXT,
...> author TEXT,
...> text TEXT
...> );
sqlite> .quit
Die Datei blogdb.schema sieht so aus:
CREATE TABLE articles (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
author TEXT,
text TEXT
);
CREATE TABLE articles_comments (
article_id INTEGER,
comment_id INTEGER,
added_time REAL,
PRIMARY KEY (article_id, comment_id)
);
CREATE TABLE blogs (
name TEXT PRIMARY KEY,
author TEXT,
descr TEXT
);
CREATE TABLE blogs_articles (
blog_name TEXT,
article_id INTEGER,
added_time REAL,
PRIMARY KEY (blog_name, article_id)
);
CREATE TABLE comments (
id INTEGER PRIMARY KEY AUTOINCREMENT,
subject TEXT,
author TEXT,
text TEXT
);
Tragen wir testweise was ein:
$ sqlite3 /tmp/blogdb.sqlite3
SQLite version 3.4.1
Enter ".help" for instructions
sqlite> INSERT INTO blogs VALUES (
...> 'The Python Blog',
...> 'Farid Hajji',
...> 'A blog about Python, what else?'
...> );
sqlite> INSERT INTO blogs VALUES (
...> 'The Perl Blog',
...> 'Farid Hajji',
...> 'There is more than one way to do it!'
...> );
sqlite> .quit
Das sqlite3-Modul¶
Anwendung: Verwaltung von MP3-Metadaten¶
#!/usr/bin/env python
# mp3scan.py -- scan an mp3 and return a dictionary
import parseid3
import fingerprint
def scan_mp3(path_to_mp3):
"Scan an MP3 for vital data"
mp3data = {}
mp3data['path'] = path_to_mp3
try:
mp3data['sha1'] = fingerprint.compute_sha1(open(path_to_mp3, 'rb'))
except IOError, e:
print "EIO0: %s\n%s" % (path_to_mp3, e) # Permission problem?
return None
id3 = parseid3.fetch_ID3tag(path_to_mp3)
if id3 is None:
print "EID3: %s" % path_to_mp3
id3 = {}
id3['title'] = id3['artist'] = id3['album'] = id3['comment'] = 'ERROR'
id3['track'] = id3['genre'] = id3['year'] = None
mp3data.update(id3)
for key in mp3data.keys():
if mp3data[key] is None:
mp3data[key] = ''
return mp3data
if __name__ == '__main__':
import sys, pprint
if len(sys.argv) != 2:
print >>sys.stderr, "Usage:", sys.argv[0], "path/to/file.mp3"
sys.exit(1)
thepath = sys.argv[1]
pprint.pprint(scan_mp3(thepath))
#!/usr/bin/env python
# mp3tree.py -- get list of all files that end in .mp3 or .MP3
import os, os.path
def tree_mp3(path_to_root):
"A generator that returns a list of all .mp3 and .MP3 files"
for root, dirs, files in os.walk(path_to_root):
files.sort()
for fname in files:
if fname.endswith('.mp3') or fname.endswith('.MP3'):
yield os.path.join(path_to_root, root, fname)
if __name__ == '__main__':
import sys
if len(sys.argv) != 2:
print >>sys.stderr, "Usage:", sys.argv[0], "dir"
sys.exit(1)
rootpath = sys.argv[1]
print '\n'.join(tree_mp3(rootpath))
Benötigt werden auch folgende Module:
#!/usr/bin/env python
# mp3initdb_sqlite3.py -- create mp3collection schemas in SQLite3
import sqlite3
MP3META_SCHEMA = '''
CREATE TABLE mp3meta (
id TEXT PRIMARY KEY,
title TEXT,
artist TEXT,
album TEXT,
track INTEGER,
genre INTEGER,
comment TEXT,
year TEXT
);
'''
MP3PATHS_SCHEMA = '''
CREATE TABLE mp3paths (
id TEXT NOT NULL,
path TEXT NOT NULL
);
'''
MP3PATHS_INDEX_SCHEMA = '''
CREATE UNIQUE INDEX unique_index ON mp3paths ( id, path );
'''
def create_schema(path_to_db):
"Create the SQLite3 database schema"
conn = sqlite3.connect(path_to_db)
curs = conn.cursor()
curs.execute(MP3META_SCHEMA)
curs.execute(MP3PATHS_SCHEMA)
curs.execute(MP3PATHS_INDEX_SCHEMA)
curs.close()
conn.close()
if __name__ == '__main__':
import sys
if len(sys.argv) != 2:
print >>sys.stderr, "Usage:", sys.argv[0], "path/to/mp3collectiondb"
sys.exit(1)
path_to_db = sys.argv[1]
create_schema(path_to_db)
#!/usr/bin/env python
# mp3db_sqlite3.py -- update mp3collection database from mp3 meta data
import sqlite3
from mp3scan import scan_mp3
from mp3tree import tree_mp3
def update_database(path_to_db, root, debug=False):
"Update database, starting from root path"
# Open SQLite3 database and start transaction block
conn = sqlite3.connect(path_to_db, isolation_level='DEFERRED')
curs = conn.cursor()
for path in tree_mp3(root):
# Read and compute meta data of file path
m = scan_mp3(path)
if debug: print "READ(%s)" % path
if m is None: continue
# Save meta data into mp3meta
try:
curs.execute('''INSERT INTO mp3meta VALUES
(?, ?, ?, ?, ?, ?, ?, ?)''',
(m['sha1'], m['title'], m['artist'], m['album'],
m['track'], m['genre'], m['comment'], m['year']))
except sqlite3.IntegrityError, e:
print "ERR1(%s, %s):" % (m['sha1'], path), e
# Save path info of this file into mp3paths
try:
curs.execute('''INSERT INTO mp3paths VALUES (?, ?)''',
(m['sha1'], path))
except sqlite3.IntegrityError, e:
print "ERR2(%s, %s):" % (m['sha1'], path), e
# Commit transaction now
conn.commit()
# That's all, folks! Now let's clean up
curs.close()
conn.close()
if __name__ == '__main__':
import sys
if len(sys.argv) != 3:
print >>sys.stderr, "Usage:", sys.argv[0], "path_to_db path_to_root"
sys.exit(1)
path_to_db, path_to_root = sys.argv[1], sys.argv[2]
update_database(path_to_db, path_to_root, debug=True)
PostgreSQL-Anbindung mit psycopg2¶
{kind=link}
PostgreSQL installieren¶
Windows¶
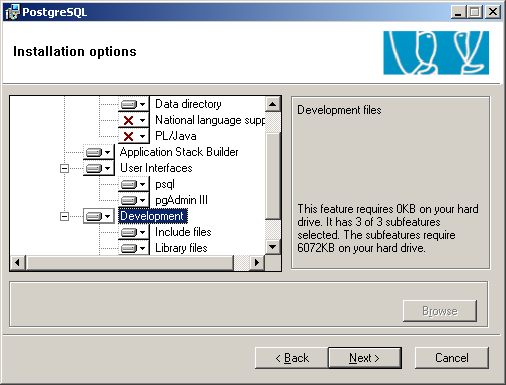
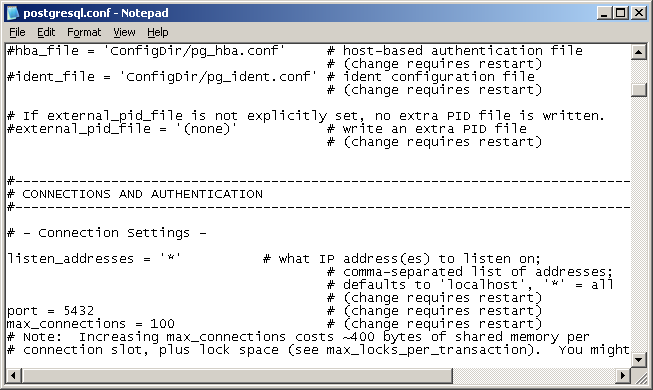
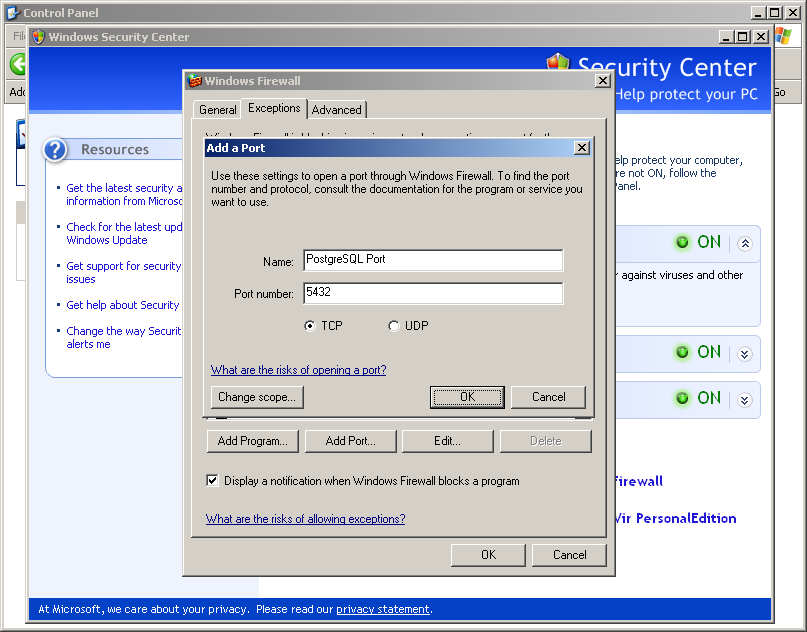
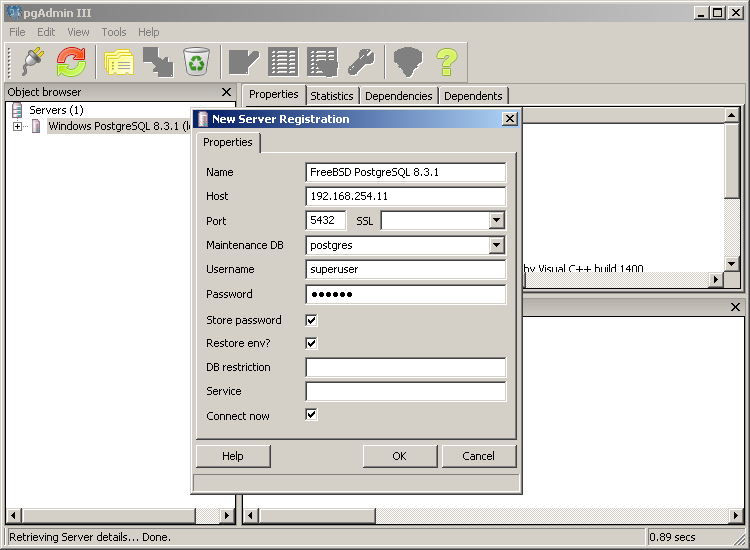
Screenshots:
- Auswahl der PostgreSQL Komponenten
- Die Datenbank-Instanz initialisieren
- Das PostgreSQL Edit pg_hba.conf Menü
- Eigenes Subnetz in die pg_hba.conf eintragen
- listen_addresses in postgresql.conf kontrollieren
- Mit psql an den FreeBSD DB-Server connecten
- Mit psql eine Abfrage dorthin senden
- Den PostgreSQL Serverport 5432 in der Windows Firewall zulassen
- In pgAdmin III den FreeBSD DB-Server anmelden
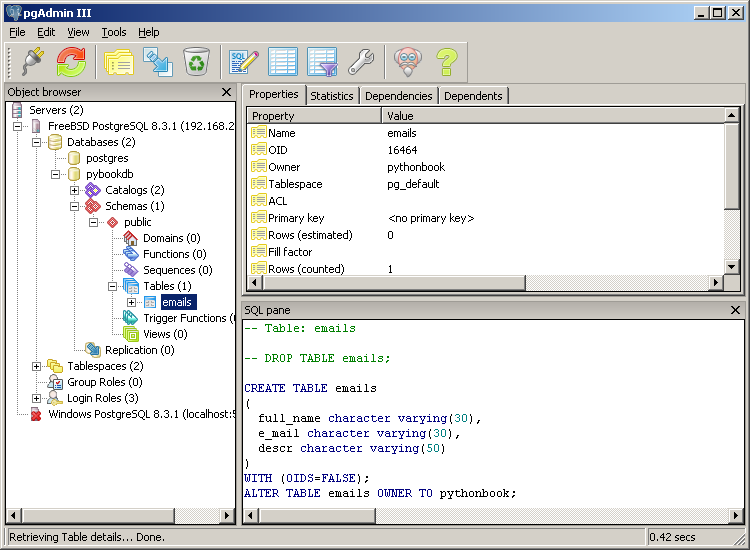
- pgAdmin III’s Sicht auf die emails Tabelle
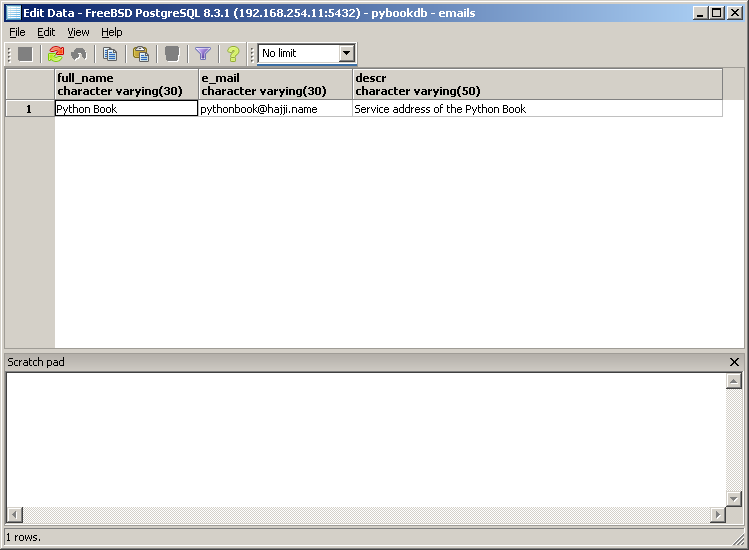
- Editierbare Tabelle mit pgAdmin III
- Mit createuser und createdb Benutzer und DB auf dem Windows-DBServer erzeugen
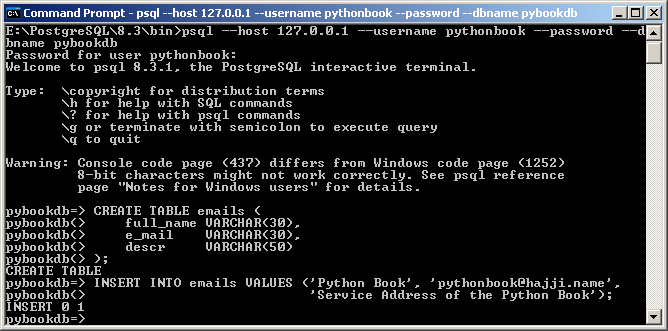
- Auf dem Windows-DBServer die Tabelle emails erzeugen
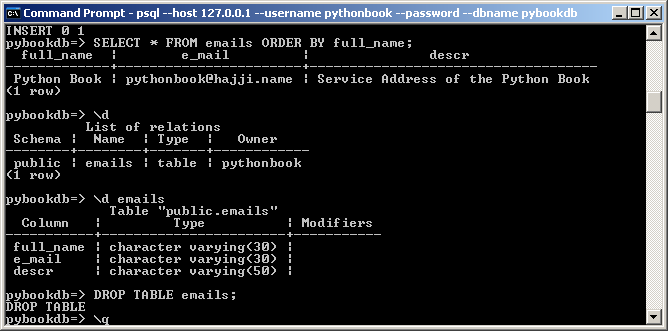
- Auf dem Windows-DBServer die Tabelle emails abfragen und löschen
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
psycopg2 installieren¶
psycopg2 unter Unix installieren¶
URLs:
- Die im Buch verwendete Version von psycopg2 (mit
easy_install psycopg2wird aber die neueste Version installiert)
Der Patch für FreeBSD:
--- psycopg/config.h.orig 2007-04-11 12:12:37.000000000 +0000
+++ psycopg/config.h 2007-07-02 14:41:35.000000000 +0000
@@ -113,7 +113,7 @@
#define inline
#endif
-#if defined(__FreeBSD__) || (defined(_WIN32) && !defined(__GNUC__)) \
|| defined(__sun__)
+#if (defined(_WIN32) && !defined(__GNUC__)) || defined(__sun__)
/* what's this, we have no round function either? */
static double round(double num)
{
psycopg2 unter Windows installieren¶
URLs:
- Ein vorkompiliertes Modul für Windows (
win-psycopgProjekt)
Screenshots:
{kind=link}
{kind=link}
{kind=link}
Anwendung: MP3-Metadaten unter PostgreSQL¶
#!/usr/bin/env python
# mp3initdb_pgsql.py -- create mp3collection schemas in PostgreSQL
import psycopg2
MP3META_SCHEMA = '''
CREATE TABLE mp3meta (
id CHAR(40) PRIMARY KEY,
title VARCHAR(30),
artist VARCHAR(30),
album VARCHAR(30),
track VARCHAR(3),
genre VARCHAR(3),
comment VARCHAR(30),
year VARCHAR(4)
);
'''
MP3PATHS_SCHEMA = '''
CREATE TABLE mp3paths (
id CHAR(40) NOT NULL REFERENCES mp3meta(id),
path VARCHAR(255) NOT NULL
);
'''
MP3PATHS_INDEX_SCHEMA = '''
CREATE UNIQUE INDEX unique_index ON mp3paths ( id, path );
'''
def create_schema(dsn):
"Create the tables within the pybookdb database"
conn = psycopg2.connect(dsn)
curs = conn.cursor()
curs.execute(MP3META_SCHEMA)
curs.execute(MP3PATHS_SCHEMA)
curs.execute(MP3PATHS_INDEX_SCHEMA)
conn.commit()
curs.close()
conn.close()
if __name__ == '__main__':
from getpass import getpass
DSN = "dbname='pybookdb' user='pythonbook' host='127.0.0.1' " + \
"password='%s'" % (getpass("Enter password for pythonbook: "),)
print "Schema(%s)" % (DSN,)
create_schema(DSN)
#!/usr/bin/env python
# mp3db_pgsql.py -- update mp3collection database from mp3 meta data
import psycopg2
from mp3scan import scan_mp3
from mp3tree import tree_mp3
def update_database(dsn, root, debug=False):
"Update database dsn, starting from root path"
# Open PostgreSQL database and start transaction block
conn = psycopg2.connect(dsn)
curs = conn.cursor()
for path in tree_mp3(root):
# Read and compute meta data of file path
m = scan_mp3(path)
if debug: print "READ(%s)" % path
if m is None: continue
# Save meta data into mp3meta
try:
curs.execute('''INSERT INTO mp3meta VALUES
(%(sha1)s, %(title)s, %(artist)s, %(album)s,
%(track)s, %(genre)s, %(comment)s, %(year)s)''', m)
except psycopg2.DatabaseError, e:
print "ERR1(%s, %s):" % (m['sha1'], path), e
conn.commit()
# Save path info of this file into mp3paths
try:
curs.execute("INSERT INTO mp3paths VALUES (%(sha1)s, %(path)s)", m)
except psycopg2.DatabaseError, e:
print "ERR2(%s, %s):" % (m['sha1'], path), e
conn.commit()
# That's all, folks! Now let's clean up
curs.close()
conn.close()
if __name__ == '__main__':
from getpass import getpass
import sys
if len(sys.argv) != 2:
print >>sys.stderr, "Usage:", sys.argv[0], "path_to_root"
sys.exit(1)
path_to_root = sys.argv[1]
DSN = "dbname='pybookdb' user='pythonbook' host='127.0.0.1' " + \
"password='%s'" % (getpass("Enter password for pythonbook: "),)
update_database(DSN, path_to_root, debug=True)
MySQL-Anbindung mit MySQLdb¶
URLs:
MySQL-python installieren¶
URLs:
- MySQL-python Homepage (aber besser mit
easy_install MySQL-pythoninstallieren)
Unix¶
{kind=link}
MySQL-python benutzen¶
Anwendung: MP3-Metadaten unter MySQL¶
#!/usr/bin/env python
# mp3initdb_MySQLdb.py -- create mp3collection schemas in MySQL
import MySQLdb
MP3META_SCHEMA = '''
CREATE TABLE mp3meta (
id CHAR(40) PRIMARY KEY,
title VARCHAR(30),
artist VARCHAR(30),
album VARCHAR(30),
track VARCHAR(3),
genre VARCHAR(3),
comment VARCHAR(30),
year VARCHAR(4)
) ENGINE = "InnoDB";
'''
MP3PATHS_SCHEMA = '''
CREATE TABLE mp3paths (
id CHAR(40) NOT NULL,
path VARCHAR(255) NOT NULL,
FOREIGN KEY (id) REFERENCES mp3meta(id)
) ENGINE = "InnoDB";
'''
MP3PATHS_INDEX_SCHEMA = '''
CREATE UNIQUE INDEX unique_index ON mp3paths ( id, path );
'''
def create_schema(dsn):
"Create the tables within the pybookdb database"
conn = MySQLdb.connect(user=dsn['user'], passwd=dsn['passwd'],
host=dsn['host'], db=dsn['dbname'])
curs = conn.cursor()
curs.execute(MP3META_SCHEMA)
curs.execute(MP3PATHS_SCHEMA)
curs.execute(MP3PATHS_INDEX_SCHEMA)
conn.commit()
curs.close()
conn.close()
if __name__ == '__main__':
from getpass import getpass
DSN = { 'user': 'pythonbook', 'passwd': getpass("Enter db password: "),
'host': '127.0.0.1', 'dbname': 'pybookdb' }
print "Schema(%s)" % (DSN,)
create_schema(DSN)
#!/usr/bin/env python
# mp3db_mysql.py -- update mp3collection database from mp3 meta data
import MySQLdb
from mp3scan import scan_mp3
from mp3tree import tree_mp3
def update_database(dsn, root, debug=False):
"Update database dsn, starting from root path"
# Open MySQL database and start transaction block
conn = MySQLdb.connect(user=dsn['user'], passwd=dsn['passwd'],
host=dsn['host'], db=dsn['dbname'])
curs = conn.cursor()
for path in tree_mp3(root):
# Read and compute meta data of file path
m = scan_mp3(path)
if debug: print "READ(%s)" % path
if m is None: continue
# Save meta data into mp3meta
try:
curs.execute('''INSERT INTO mp3meta VALUES
(%(sha1)s, %(title)s, %(artist)s, %(album)s,
%(track)s, %(genre)s, %(comment)s, %(year)s)''', m)
except MySQLdb.DatabaseError, e:
print "ERR1(%s, %s):" % (m['sha1'], path), e
conn.commit()
# Save path info of this file into mp3paths
try:
curs.execute("INSERT INTO mp3paths VALUES (%(sha1)s, %(path)s)", m)
except MySQLdb.DatabaseError, e:
print "ERR2(%s, %s):" % (m['sha1'], path), e
conn.commit()
# That's all, folks! Now let's clean up
curs.close()
conn.close()
if __name__ == '__main__':
from getpass import getpass
import sys
if len(sys.argv) != 2:
print >>sys.stderr, "Usage:", sys.argv[0], "path_to_root"
sys.exit(1)
path_to_root = sys.argv[1]
DSN = { 'user': 'pythonbook', 'passwd': getpass("Enter db password: "),
'host': '127.0.0.1', 'dbname': 'pybookdb' }
update_database(DSN, path_to_root, debug=True)
Der objektrelationale Mapper SQLObject¶
{kind=link}
SQLObject installieren¶
URLs:
- Die im Buch benutze Version von SQLObject (aber besser
easy_install SQLObjectaufrufen) - Als Abhängigkeit wurde FormEncode installiert (aber s. oben)
Screenshots:
{kind=link}
SQLObject benutzen¶
{kind=link}
Eine persistente Klasse definieren¶
Definieren wir als Beispiel die Klasse Comment:
class Comment(SQLObject):
subject = StringCol(length=50)
body = StringCol()
author = StringCol(default='Anonymous')
added = DateTimeCol(default=DateTimeCol.now)
Screenshots:
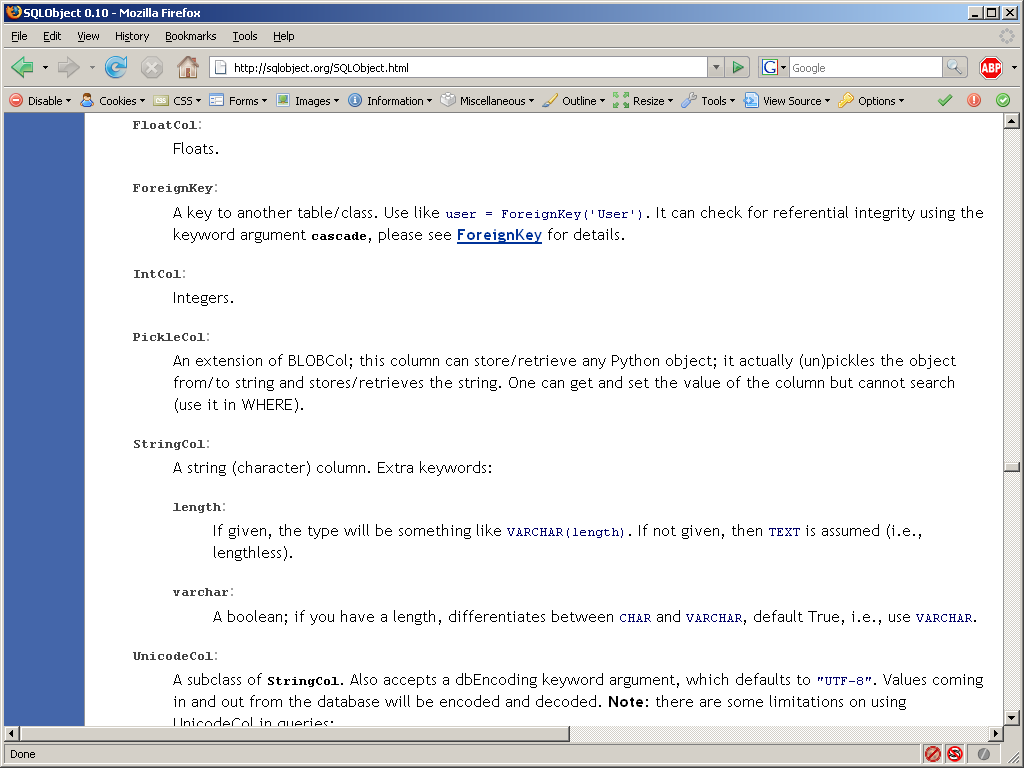{kind=link}
Die Datenbank abfragen¶
1:N- und N:M-Beziehungen¶
Eine 1:N-Beziehung:
class Person(SQLObject):
name = StringCol()
contacts = MultipleJoin('Contact')
class Contact(SQLObject):
email = StringCol()
phone = StringCol()
person = ForeignKey('Person')
Person.createTable()
Contact.createTable()
Eine N:M-Beziehung:
class Employee(SQLObject):
name = StringCol()
roles = RelatedJoin('Role')
class Role(SQLObject):
descr = StringCol()
employees = RelatedJoin('Employee')
Das Blog-System mit SQLObject¶
#!/usr/bin/env python
# soblogs.py -- A blogs system with SQLObject
from sqlobject import *
dsn = 'postgres://pythonbook:py.book@127.0.0.1/pybookdb'
class SoBlogs(object):
def __init__(self, createTables=False, debug=False):
self.dsn = dsn
self.conn = connectionForURI(self.dsn)
self.conn.debug = debug
sqlhub.processConnection = self.conn
if createTables:
Blog.createTable()
Article.createTable()
Comment.createTable()
class Blog(SQLObject):
name = StringCol()
author = StringCol()
descr = StringCol()
added = DateTimeCol(default=DateTimeCol.now)
articles = MultipleJoin('Article')
class Article(SQLObject):
title = StringCol()
author = StringCol()
text = StringCol()
added = DateTimeCol(default=DateTimeCol.now)
blog = ForeignKey('Blog')
comments = MultipleJoin('Comment')
class Comment(SQLObject):
subject = StringCol()
author = StringCol()
text = StringCol()
added = DateTimeCol(default=DateTimeCol.now)
article = ForeignKey('Article')
Eine typische Sitzung:
from sqlobject import *
from soblogs import *
SoBlogs(createTables=True, debug=False)
b = Blog(name='SQLObject Blog', author='Farid Hajji',
descr='A blog to discuss SQLObject issues')
a1 = Article(title='Installing SQLObject is easy', author='Farid',
text='Just run "easy_install SQLObject" to install',
blog=b)
a2 = Article(title='Joins in SQLObject', author='A Blogger',
text='Use ForeignKey and MultipleJoin for 1:N',
blog=b)
a3 = Article(title='Joins in SQLObject (II)', author='A Blogger',
text='Use RelatedJoin on both sides of a N:M relationship',
blog=b)
c11 = Comment(subject='URL needed', author='Anonymous',
text='Need to add an -f URL to easy_install',
article=a1)
Screenshots:
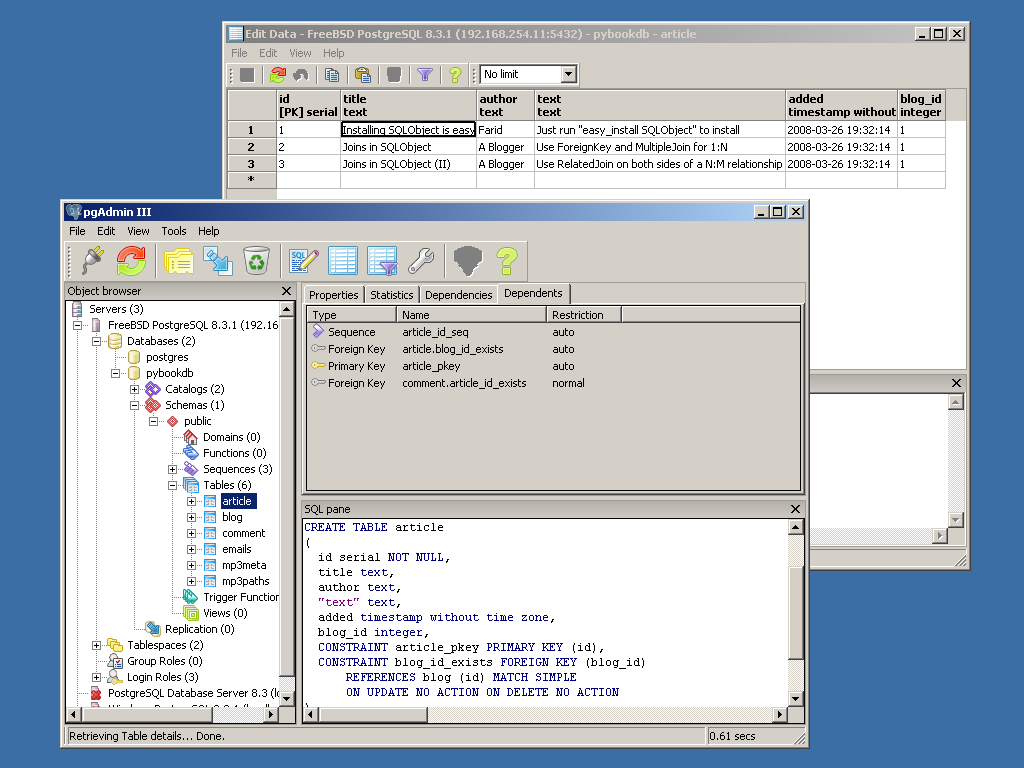{kind=link}
{kind=link}